第1章 简介¶
当我们思考学习的本质时,我们首先想到的是通过与环境交互来学习。 当一个婴儿玩耍,挥动手臂或环顾四周时,他没有明确的老师,但他确实通过直接的感觉与环境联系。 他可以通过这种联系获得大量关于因果关系、动作的结果以及如何实现目标的信息。 在我们的生活中,这种交互无疑是环境和自身知识的主要来源。 无论我们是学习驾驶汽车还是进行交谈,我们都敏锐地意识到我们的环境如何响应我们的行为,并且我们试图通过我们的行为来影响所发生的事情。 从交互中学习是几乎所有学习和智能理论的基本思想。
在本书中,我们探索了一种从交互中学习的 计算 方法。 我们主要探索理想化的学习情境并评估各种学习方法的有效性,而不是直接理解人或动物的学习方式 [1] 。 也就是说,我们采用人工智能研究员或工程师的观点。 我们探索在解决科学或经济效益的学习问题方面有效的机器设计,通过数学分析或计算实验评估设计。 我们探索的方法称为 强化学习,更侧重于从交互中进行目标导向的学习,而不是其他机器学习方法。
| [1] | 第14章和第15章总结了心理学和神经科学的关系。 |
1.1 强化学习¶
强化学习是一种学习如何将状态映射到动作,以获得最大奖励的学习机制。 学习者不会被告知要采取哪些动作,而是必须通过尝试来发现哪些动作会产生最大的回报。 在最有趣和最具挑战性的案例中,动作不仅可以影响直接奖励,还可以影响下一个状态,并通过下一个状态,影响到随后而来的奖励。 这两个特征 - 试错法和延迟奖励 - 是强化学习的两个最重要的可区别特征。
强化学习,就像许多名称以“ing”结尾的主题一样,例如机器学习和登山,同时也是一个问题,一类能够很好地解决问题的解决方法,以及研究这个问题及其解决方法的领域。 为所有三件事情使用单一名称是方便的,但同时必须保持三者(问题,方法,领域)在概念上分离。 特别的,在强化学习中,区分问题和解决问题的方法是非常重要的;没有做出这种区分是许多混乱的根源。
我们使用动态规划理论的思想来规范化强化学习的问题,具体地说,是不完全已知的马尔可夫决策过程的最优控制。 这种规范化的详细描述将在第3章,但是最基本的思想是:采样实际问题最重要的方面,训练一个个体多次与环境交互去达成一个目标。 个体必须能够在某种程度上感知其环境状态,并且能够采取动作影响环境的状态。 个体还必须具有与环境状态相关的一个或多个目标。 马尔科夫决策过程基本概念无差别地包含感知,动作和目标三个方面。 我们认为任何非常适合解决此类问题的方法都是一种强化学习方法。
强化学习不同于 监督学习。 监督学习是目前机器学习领域中研究最多的一种学习方式,它从知识渊博的教练所提供的有标记的训练集中学习。 每一个样例都是一种情况的描述,都带有标签,标签描述的是系统在该情况下的应该采取的正确动作,每一个样例用来识别这种情况应该属于哪一类。 这种学习的目的是让系统推断概括它应有的反馈机制,使它可以对未知样本作出正确回应。 这是一种重要的学习方式,但单凭它并不足以从交互中学习。 在交互问题中,找到期待的既正确又典型的样例通常都是不切实际的。 在一个未知的领域,若要使收益最大化,个体必须能够从自己的经验中学习。
强化学习也与机器学习研究人员所谓的 无监督学习 不同,后者通常是用于寻找隐藏在未标记数据集合中的结构。 监督学习和无监督学习这两个术语似乎对机器学习范式进行了详尽的分类,但事实却并非如此。 尽管人们可能会试图将强化学习视为一种无监督学习,因为它不依赖于正确行为的样例,但强化学习试图最大化奖励信号而不是试图找到隐藏的结构。 在个体的经验数据中揭示结构确实对强化学习特别有用,但是它本身并没有解决最大化奖励信号的强化学习问题。 因此,我们认为强化学习是除监督学习和无监督学习之外的第三种机器学习范式,也许还有其他范式。
在强化学习中出现而在其他类型学习中未出现的挑战之一,是如何权衡探索(Exploration)与利用(Exploitation)之间的关系。 为了获得大量奖励,强化学习个体必须倾向于过去已经尝试过并且能够有效获益的行动。 但是要发现这样的行为,它必须尝试以前没有选择过的行为。 个体必须充分 利用 它既有经验以获得收益,但它也必须 探索,以便在未来做出更好的动作选择。 困境在于,任何探索和利用都难以避免失败。 个体必须尝试各种动作,逐步地选择那些看起来最好的动作。 在随机任务中,每一个动作必须经过多次尝试才能得到可靠的预期收益。 几十年来,数学家一直在深入研究探索利用困境,但仍未得到解决。 就目前而言,在监督和无监督的学习中,至少在这些范式的最纯粹的形式中,完全平衡探索和利用的项目尚未出现。
强化学习的另一个关键特征是它明确地考虑了目标导向的个体与不确定环境相互作用的 整个 问题。 这与许多考虑子问题但没有解决它们如何融入更大的图景的方法形成对比。 例如,我们已经提到很多机器学习研究都关注监督学习而没有明确说明这种能力最终如何有用。 其他研究人员已经发展了具有总体目标的规划理论,但没有考虑规划在实时决策中的作用,也没有考虑规划所需的预测模型来自何处。 尽管这些方法已经产生了许多有用的结果,但它们一个重要的限制在于过多关注孤立子问题。
强化学习采取相反的策略,它具有一个完整的、交互式的、寻求目标(goal-seeking)的个体。 所有强化学习个体都有明确的目标,可以感知环境的各个方面,并可以选择影响其环境的动作。 此外,尽管个体面临的环境有很大的不确定性,通常从一开始就假设个体必须采取动作。 当强化学习涉及规划时,它必须解决规划和实时动作选择之间的相互作用,以及如何获取和改进环境模型的问题。 当强化学习涉及监督学习时,它要确定决定哪些能力是关键的,哪些是不重要。 为了学习研究以取得进步,必须隔离和研究重要的子问题,即使不能体现所有完整的细节,它们也应该是在完整的、交互式的、寻求目标的个体中有明确功能的子问题。
一个完整的、交互式的、寻求目标的个体,并不总是意味着像是一个完整的有机体或机器人。 这里有许多明显的例子,但是一个完整的、交互式的、寻求目标的个体也可以是更大行为系统的一个组成部分。 在这种情况下,个体直接与较大系统的其余部分交互,并间接与较大系统的环境交互。 一个简单的例子是一个监控机器人电池的充电水平并向机器人的控制架构发送命令的个体。 这个个体的环境是机器人的其余部分以及机器人的环境。 人们的眼光应超越最明显的个体及其环境的例子,才能理解强化学习框架的普遍性。
现代强化学习最激动人心的一个方面是与其他工程和科学学科的实质性和富有成效的交互。 强化学习是人工智能和机器学习领域长达数十年的一个趋势,它与统计学、最优化和其他数学学科更紧密地结合在一起。 例如,某些强化学习方法学习参数的能力解决了运筹学与控制论中的经典“维数灾难”问题。 更有特色的是,强化学习也与心理学和神经科学有着紧密的联系,双方均有获益。 在所有形式的机器学习中,强化学习最接近人类和其他动物所做的学习,而强化学习的许多核心算法最初都受到生物学习系统的启发。 通过动物学习的心理模型返回更符合经验数据的结果,以及通过一部分大脑奖励系统的有影响力的模型,强化学习也得到了反馈。 本书正文介绍了与工程和人工智能相关的强化学习的思想,并在第14章和第15章中总结了与心理学和神经科学的联系。
最后,强化学习也在某种程度上符合人工智能回归简单的一般性原则的大趋势。 自20世纪60年代后期以来,许多人工智能研究人员认为普遍性的原则是不存在的,而智能则归因于拥有大量特殊用途的技巧,过程和启发式方法。 有人说,如果我们能够将相关的事实充分地提供给一台机器,比如一百万或十亿,那么它就会变得聪明起来。 基于一般性原则(如搜索或学习)的方法被定性为“弱方法”,而基于特定知识的方法被称为“强方法”。 这种观点在今天仍然很普遍,但并不占优势。 从我们的观点来看,这只是一个不成熟的过程:寻找一般性原则的努力太少,以至于没有结论。 现代人工智能现在包括许多寻找在学习,搜索和决策方面的一般性原则的研究。 目前还不清楚钟摆会摆动多远,但强化学习研究肯定是摆向更简单和更少的人工智能一般原则的钟摆的一部分。
1.2 例子¶
理解强化学习的一个好方法是思考指导其发展的一些例子和可能的应用。
- 国际象棋大师落子。落子决定既通过规划 - 期待的回复和逆向回复 (anticipating possible replies and counterreplies),也出于对特定位置和移动及时直觉的判断。
- 自适应控制器实时调节炼油厂操作的参数。控制器在指定的边际成本的基础上优化产量/成本/质量交易,而不严格遵守工程师最初建议的设定。
- 一头瞪羚在出生后几分钟挣扎着站起来。半小时后,它能以每小时20英里的速度奔跑。
- 移动机器人决定是否应该进入新房间以寻找和收集更多垃圾来,或尝试回到充电站充电。 它根据电池的当前电池的充电水平,以及过去能够快速轻松地找到充电站的程度做出决定。
- 菲尔准备他的早餐。仔细检查,即使是这个看似平凡的行动,也会发现一个复杂的条件行为网和互锁的目标-子目标关系: 走到橱柜,打开它,选择一个麦片盒,然后伸手去拿,抓住并取回盒子。 拿到碗,勺子和牛奶盒也需要其他复杂的,调整的,交互的行为序列来完成。每个步骤都涉及一系列眼球运动,以获取信息并指导到达和移动。 它们需要对于如何拿住物品或者在拿其他物品之前将它们中的一些运送到餐桌上做出快速判断。 每个步骤都以目标为指导并为其他目标服务,例如抓起勺子或走到冰箱,比如一旦麦片准备好就拿勺子吃以最终获得营养。 无论他是否意识到这一点,菲尔都在获取有关他身体状况的信息,这些信息决定了他的营养需求,饥饿程度和食物偏好。
这些例子共同的特征非常基础,以至于很容易被忽略。 所有这些都涉及积极的决策个体与其环境之间的 交互,个体于存在不确定性的环境中寻求实现 目标。 个体的行为能影响未来的环境状态(例如,下一个国际象棋位置,炼油厂的水库水位,机器人的下一个位置以及其电池的未来充电水平),从而影响个体之后可以采取的动作和机会。 正确的选择需要考虑到动作的间接延迟后效应,因此可能需要预见或规划。
同时,在所有这些例子中,动作的效果都无法被完全预测;因此,个体必须经常监控其环境并做出适当的反应。 例如,菲尔必须观察他倒入麦片的碗中的牛奶以防止溢出。 所有这些例子都涉及明确的目标,即个体可以根据其直接感知的内容判断完成目标的进度。 国际象棋选手知道他是否获胜,炼油厂控制员知道生产了多少石油,瞪羚小牛知道它何时倒下,移动机器人知道它的电池何时耗尽,菲尔知道他是否正在享用他的早餐。
在所有这些例子中,个体可以使用其经验来改善其性能。 国际象棋选手改进了他用来评估位置的直觉,从而改善了他的发挥;瞪羚提高了它的活力;菲尔学会精简他的早餐。 个体在任务开始时所具有的知识 - 无论是之前的相关任务经验还是通过设计或演变带来的 - 都会影响有用或易于学习的内容, 但与环境的交互对于调整行为以利用任务的特性至关重要。
1.3 强化学习的要素¶
在个体和环境之外,强化学习系统一般有四个要素:策略,奖励信号,价值函数,和可选的环境 模型。
策略 定义了学习个体在给定时间内的行为方式。 简单来说,策略是从感知的环境状态到在这些状态下要采取的行动的映射。 它对应于心理学中所谓的一组刺激-反应规则或关联。 在某些情况下,策略可以是简单的函数或查找表格,而在其他情况下,它可能涉及广泛的计算,例如搜索过程。 策略是强化学习个体的核心,因为它本身就足以确定行为。一般来说,策略对指定每个动作的概率而言可以是随机的。
奖励信号 定义了强化学习问题的目标。 在每个时间步骤,环境向强化学习个体发送的单个数字称为 奖励。 个体的唯一目标是最大化其长期收到的总奖励。 因此,奖励信号定义了相对个体而言的好和坏。 在生物系统中,我们可能会认为奖励类似于快乐或痛苦的经历。 它们是个体所面临的问题的直接和明确的特征。 奖励信号是改变策略的主要依据,如果策略选择的动作之后是低奖励,则可以更改策略以在将来选择该情况下的某些其他动作。 通常,奖励信号可以是环境状态和所采取的动作的随机函数。
虽然奖励信号表明了直接意义上的好处,但 价值函数 指定了长期收益。 粗略地说,一个状态的价值是个体从该状态开始在未来可以预期累积的收益总额。 虽然奖励决定了环境状态的直接,内在的价值,但价值表明了在考虑了可能遵循的状态和这些状态下可获得的奖励之后各状态的 长期 价值。 例如,一个状态可能总是会产生较低的即时奖励,但仍然具有较高的价值,因为其后的状态经常会产生高回报。 或者与此相反。 以人类作类比,奖励有点像快乐(如果是高的奖励)和痛苦(如果是低的奖励),而价值则对应于我们对环境处于特定状态的高兴或不满的更精确和更有远见的判断。
奖励在某种意义上是主要的,而作为奖励预测的价值是次要的。 没有奖励就没有价值,估算价值的唯一目的就是获得更多回报。 然而,在制定和评估决策时,我们最关心的是价值。 行动选择基于价值判断。 我们寻求带来最高价值状态的行动,而不是最高奖励状态的行动,因为从长远来看,这些行动会为我们带来最大的回报。 不幸的是,确定价值要比确定奖励要困难得多。 奖励基本上由环境直接给出,但必须根据个体在其整个生命周期中所做的观察序列来估计和重新估计价值。 事实上,我们考虑的几乎所有强化学习算法中最重要的组成部分是一种有效估计价值的方法。 价值估计的核心作用可以说是过去六十年中有关强化学习的最重要的事情。
一些强化学习系统具有第四个也是最后一个要素,即环境 模型。 这是对环境的模拟,或者更一般地说,它对环境的行为做出推断。 例如,给定状态和动作,模型可以预测结果的下一状态和下一个奖励。 模型用于 规划,我们指的是在实行动前对未来进行预判。 使用模型和规划解决强化学习问题的方法被称为 基于模型 的方法,而不是更简单的 不基于模型 方法, 不基于模型方法几乎被看作是规划的 反面,它通过试错进行学习。 在第8章中,我们将探索强化学习系统,它们通过试错来学习,学习环境模型,并使用模型进行规划。 现代强化学习已经从低级的、试错学习跨越到高层次的、有计划的学习。
1.4 局限性和范围¶
强化学习在很大程度上依赖于状态的概念 - 作为策略和价值函数的输入,以及模型的输入和输出。 非正式地,我们可以将状态视为向个体传达某种特定时间“环境如何”的信号。 我们在这里使用的状态的正式定义由第3章中提出的马尔可夫决策过程的框架给出。 然而,更一般地,我们鼓励读者遵循非正式意义并将状态视为个体对其环境所能获得的任何信息。 实际上,我们假设状态信号是由某些预处理系统产生的,而预处理系统是个体环境的一部分。 在本书中,我们没有讨论构造、改变或学习状态信号的问题(除了第17.3节中的简要说明)。 我们采用这种方法并不是因为我们认为状态不重要,而是为了完全关注决策问题。 换句话说,我们在本书中的关注不是设计状态信号,而是设计行为函数以应对各种状态。
我们在本书中所考虑的大部分强化学习方法都是围绕估计价值函数构建的,但它对于解决强化学习问题而言并不是必须的。 例如,诸如遗传算法,遗传规划,模拟退火和其他优化方法的解决方法已被用于研究强化学习问题,而不必求助于价值函数。 这些方法应用多个静态策略,每个策略在较长时间内与单独的环境实例进行交互。 获得最多奖励的策略及其随机变化将延续到下一代策略,并重复该过程。 我们称这些方法为进化方法是因为它们的行为类似于生物进化方式,这种方式产生具有熟练行为的生物,即使它们在个体生命期间内不学习。 如果策略空间足够小,或者容易被构造,或者如果有大量的时间可用于搜索,那么进化方法可能是有效的。 此外,进化方法在学习个体不能感知环境的完整状态的问题上具有优势。
我们的重点是强化学习方法,这些方法在与环境交互时学习,而进化方法则不然。 在许多情况下,能够利用个体行为交互细节的方法比进化方法更有效。 进化方法忽略了对大量的强化学习问题有用的结构:他们没有利用策略是从状态到行动的映射这一事实;他们并没有注意到个体生命周期中所经历的状态和采取的行动。 在某些情况下,这些信息可能会产生误导(例如,当状态不确定的时候),但更经常的是它能使搜索更有效率。 虽然进化和学习有许多共同的特性并且自然地协同工作,但我们并不认为进化方法本身特别适合强化学习问题,因此,我们不在本书中讨论它们。
1.5 拓展例子:井字棋¶
为了说明强化学习的一般概念并将其与其他方法进行对比,我们接下来将详细地考虑一个简单的例子。
考虑熟悉的孩子玩的井字棋游戏。两名玩家轮流在一个三乘三的棋盘上比赛。 一个玩家画叉,另一个画圈,若叉或圈的连续三个棋子落于一行或一列或同一斜线上则获胜;若棋盘被填满了也不能决出胜负则为平局。 因为熟练的玩家可以从不丢棋,让我们假设我们正在与一个不完美的玩家对战,他的战术有时是不正确的,并且允许我们获胜。 而且,让我们考虑平局和输棋对我们同样不利。 我们如何构建一个能够在比赛中发现对手的漏洞并且学会最大化获胜机率的玩家呢?
虽然这是一个简单的问题,但是通过传统方法不能以令人满意的方式解决。 例如,来自博弈论的经典的“极小极大(minimax)”解决方案在这里是不正确的,因为它假定了对手使用特定的玩法。 例如,“极小极大”玩家永远不会达到可能失棋子的游戏状态,即使事实上它总是因为对手的错误游戏而从该状态获胜。 经典的连续决策问题的最优方法,例如动态规划,可以为任何对手 计算 最优解,但需要输入该对手的完整信息,包括对手在每个棋盘状态下进行每次移动的概率。 让我们假设在这个问题中无法获得这些先验信息,因为它不适用于大多数实际问题。 另一方面,可以根据经验来估计这样的信息,在这个例子上就是和对手下许多盘棋。 关于在这个问题上可以做的最好的过程是首先学习对手的行为模型,达到某种程度的置信度,然后应用动态规划来计算近似对手模型的最优解。 最后,这与我们在本书后面讨论的一些强化学习方法没有什么不同。
应用于该问题的进化方法将直接搜索可能策略的空间,以找到取胜对手的高概率。 在这里,策略是一个规则,告诉玩家为每个游戏状态做出什么样的动作,即在三乘三的棋盘上所有可能的叉和圈的摆放位置。 对于所考虑的每个策略,通过与对手进行一些比赛来获得其获胜概率的估计。然后,该评估将指导接下来考虑的策略。 一种典型的进化方法是将在策略空间中进行爬坡,然后在尝试进步的过程中依次生成和评估策略。 或者,也许可以使用遗传式算法来维护和评估一系列策略。 实际上,我们有上百种不同的优化方法。
以下是使用价值函数的方法来解决井字棋问题的方法。 首先,我们将建立一个数字表,每个数字对应一个可能的游戏状态。 每个数字都是我们从该状态获胜概率的最新估计。 我们将此估计视为状态 价值,整个表是学习的价值函数。 如果我们从A获胜的概率的当前估计值高于从B开始的概率的估计值,我们就认为状态A的价值高于状态B的,或认为状态A比状态B“更好”。 假设我们总是画叉,那么对于所有三个叉处于一行的状态的获胜概率是1,因为我们已经赢了。 类似地,对于连续三个圈处于一行或棋盘全部填满的所有状态,获胜的概率为0,因为我们无法获胜。 我们将所有其他状态的初始值设置为0.5,表示我们有50%的获胜机会。
我们和对手进行了许多场比赛。 为了选择我们的动作,我们检查每个动作可能产生的状态(在棋盘上的每个空格中有一个),并在表格中查找它们当前的值。 大多数时候,我们 贪婪地 选择具有最大价值的动作,也就是说,有最高的获胜概率。然而,偶尔我们会从其他动作中随机选择。 这些被称为 探索性 动作,因为它们使我们体验到我们可能永远不会看到的状态。 在游戏中移动和考虑的一系列动作可以如图1.1所示。
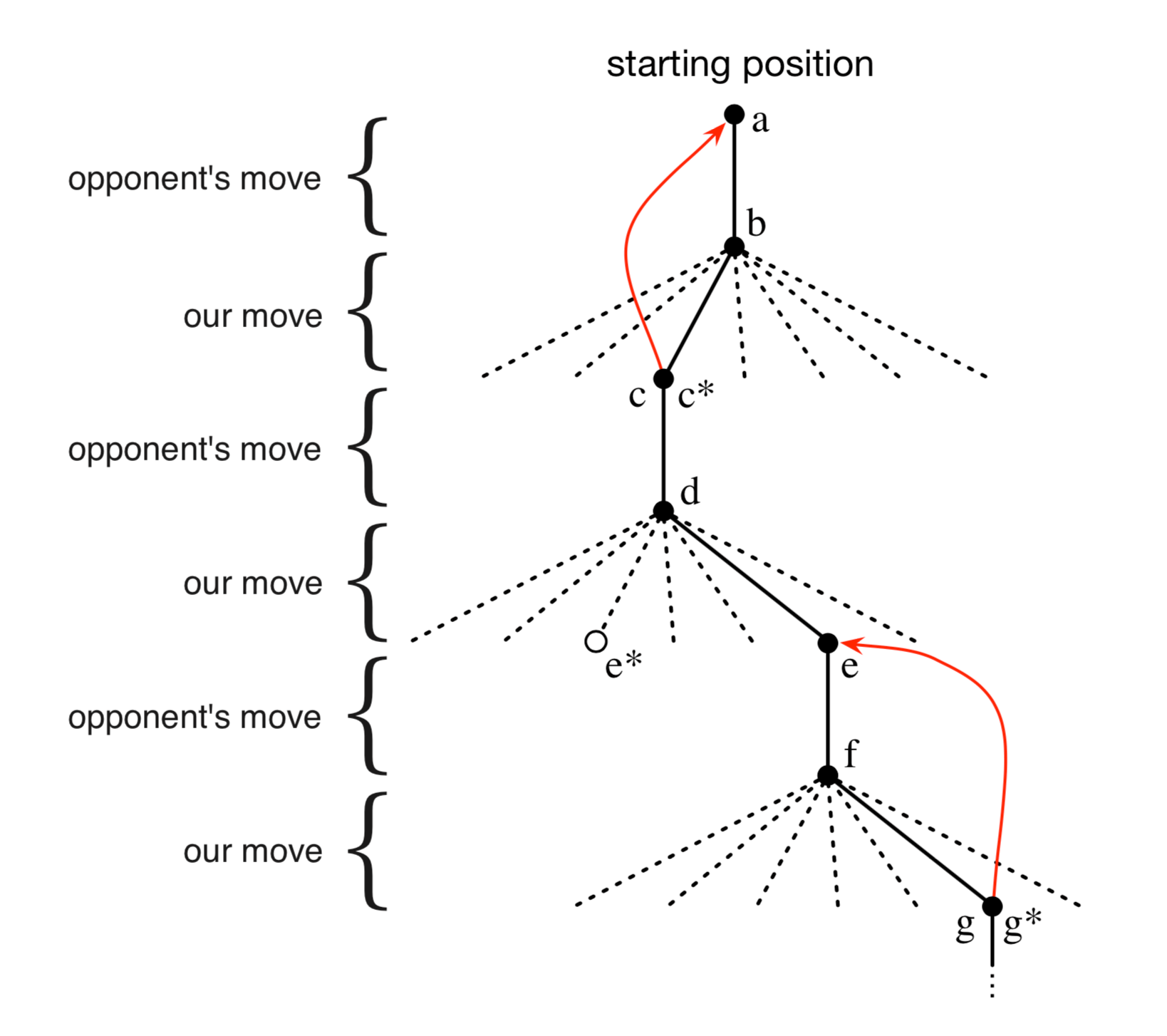
图1.1:一系列井字棋移动。黑色实线代表游戏中所采取的动作;虚线表示我们(我们的强化学习者)考虑但未做出的动作。 我们的第二步移动 \(e^{*}\) 是一次探索性的移动,这意味着 \(e^{*}\) 所表示的移动甚至优于当前移动。 探索性移动不会导致任何学习,但是我们的其他每个移动都会导致更新,如红色箭头弧线所示, 其估计价值自下而上移动到树的早期节点,如文中详述。
在我们比赛期间,我们按游戏中的发现不断改变状态的值。 我们试图让他们更准确地估计获胜的可能性。 为此,在贪婪移动后,我们重写前一状态的值,如图1.1中的箭头所示。 更准确地说,前一状态的当前值被更新为更接近后续状态的值。 这可以通过将先前状态的值移动到稍后状态的值的一小部分来完成。 如果我们让 \(S_t\) 表示贪婪移动之前的状态,而 \(S_{t+1}\) 表示移动之后的状态, 那么将 \(S_t\) 的估计值的更新表示为 \(V(S_t)\),可以写为
其中 \(\alpha\) 是小正分数,称为 步长,它影响学习速度。 此更新规则是 时序差分 学习方法的一个例子,之所以称为时序差分, 是因为其变化基于两个连续时间的估计之间的差,即 \(V(S_{t+1}) - V(S_t)\)。
上述方法在此任务上表现良好。例如,如果步长参数随着时间的推移而适当减小,那么对于任何固定的对手, 该方法会收敛于在给定玩家最佳游戏的情况下从每个状态获胜的真实概率。 此外,采取的动作(探索性动作除外)实际上是针对这个(不完美的)对手的最佳动作。 换句话说,该方法收敛于针对该对手玩游戏的最佳策略。 如果步长参数没有随着时间的推移一直减小到零,那么这个玩家也可以很好地对抗那些慢慢改变他们比赛方式的对手。
这个例子说明了进化方法和学习价值函数的方法之间的差异。 为了评估策略,进化方法保持策略固定并且针对对手进行多场游戏,或者使用对手的模型模拟多场游戏。 胜利的频率给出了对该策略获胜的概率的无偏估计,并且可用于指导下一个策略选择。 但是每次策略进化都需要多场游戏来计算概率,而且计算概率只关心最终结果,每场游戏内 的信息被忽略掉了。 例如,如果玩家获胜,那么游戏中的 所有 行为都会被认为是正确的,而不管具体移动可能对获胜至关重要。 甚至从未发生过的动作也会被认为是正确的! 相反,值函数方法允许评估各个状态。 最后,进化和价值函数方法都在搜索策略空间,但价值函数学习会利用游戏过程中可用的信息。
这个简单的例子说明了强化学习方法的一些关键特征。 首先,强调在与环境交互时学习,在这里就是与对手玩家下棋。 其次,有一个明确的目标,考虑到选择的延迟效果,正确的行为需要计划或前瞻。 例如,简单的强化学习玩家将学习如何为短视的对手设置多个行动陷阱。 强化学习解决方案的一个显着特征是它可以在不使用对手模型的情况下实现规划和前瞻的效果, 并且无需对未来状态和动作的可能序列进行精确搜索。
虽然这个例子说明了强化学习的一些关键特征,但它很简单,它可能给人的印象是强化学习比实际上更受限。 虽然井字棋游戏是一个双人游戏,但强化学习也适用于没有外部对手的情况,即在“对自然的游戏”的情况下。 强化学习也不仅限于行为分解为单独步骤的问题,例如井字棋游戏,仅在每步结束时获得奖励。 当行为无限持续并且可以随时接收各种大小的奖励时,它也是适用的。 强化学习也适用于甚至不能分解为像井字棋游戏这样的离散时间步骤的问题。 一般原则也适用于连续时间问题,虽然理论变得更加复杂,我们在这份简介中将不会介绍。
井字棋游戏具有相对较小的有限状态集,而当状态集非常大或甚至无限时,也可以使用强化学习。 例如,Gerry Tesauro(1992,1995)将上述算法与人工神经网络相结合,学习玩西洋双子棋,其具有大约 \(10^20\) 个状态。 在这么多状态中,只能经历一小部分。Tesauro的规划学得比以前的任何规划都要好得多,最终比世界上最好的人类棋手更好(第16.1节)。 人工神经网络为程序提供了从其经验中泛化的能力,以便在新状态下,它能根据其网络确定的过去面临的类似状态保存下来的信息来选择移动。 强化学习系统在如此大型状态集的问题中如何运作,与它从过去的经验中泛化的程度密切相关。 正是在这种情况中,我们最需要有强化学习的监督学习方法。 人工神经网络和深度学习(第9.6节)并不是唯一或最好的方法。
在这个井字棋游戏的例子中,学习开始时没有超出游戏规则的先验知识,但强化学习绝不是需要学习和智能的白板(a tabula rasa view)。 相反,先验信息可以以各种方式结合到强化学习中,这对于有效学习是至关重要的(例如,参见第9.5,17.4和13.1节)。 我们也可以在井字棋游戏例子中访问真实状态,而强化学习也可以在隐藏部分状态时应用,或者当学习者看到不同状态相同时也可以应用强化学习。
最后,井字棋游戏玩家能够向前看并知道每个可能移动所产生的状态。 要做到这一点,它必须拥有一个游戏模型,使其能够预见其环境如何随着它可能永远不会发生的动作变化而变化。 许多问题都是这样的,但在其他问题上,甚至可能缺乏行动效果的短期模型。 这些情况下都可以应用强化学习。模型不是必须的,但如果模型可用或可以学习,则模型可以很轻松使用(第8章)。
另一方面,也有根本不需要任何环境模型的强化学习方法。 无模型系统甚至无法预测其环境如何响应单一操作而发生变化。 对于对手来说,如果井字棋游戏玩家没有任何类型的对手的模型,则他也是无模型的。 因为模型必须合理准确才有用,所以当解决问题的真正瓶颈是构建足够精确的环境模型时,无模型方法可以优于更复杂的方法。 无模型方法同时也是基于模型方法的重要组成模块。 在我们讨论如何将它们用作更复杂的基于模型方法的组件之前,我们在本书中将用几个章节专门介绍无模型方法。
强化学习可以在系统的高级和低级层次中使用。 虽然井字棋游戏玩家只学习游戏的基本动作,但没有什么可以阻止强化学习在更高层次上工作, 其中每个“动作”本身可能是一个复杂的问题解决方法的应用。 在分层学习系统中,强化学习可以在几个层面上同时工作。
练习1.1: 自我对弈 假设上面描述的强化学习算法不是与随机对手对抗,而是双方都在学习。在这种情况下你认为会发生什么?是否会学习选择不同的行动策略?
练习1.2: 对称性 由于对称性,许多井字位置看起来不同但实际上是相同的。我们如何修改上述学习过程以利用这一点? 这种变化会以何种方式改善学习过程?现在再想一想。假设对手没有利用对称性,在这种情况下,我们应该利用吗?那么,对称等价位置是否必须具有相同的价值?
练习1.3: 贪婪地游戏 假设强化学习玩家是 贪婪的,也就是说,它总是选择使其达到最佳奖励的位置。 它可能会比一个不贪婪的玩家学得更好或更差吗?可能会出现什么问题?
练习1.4: 从探索中学习 假设在 所有 动作之后发生了学习更新,包括探索性动作。 如果步长参数随时间适当减小(但不是探索倾向),则状态值将收敛到不同的概率集。 从探索性动作中的学习,我们行动和不行动两组的计算的概率(概念上)是什么? 假设我们继续做出探索性的动作,哪一组概率可能学习得更好?哪一个会赢得更多?
练习1.5: 其他改进 你能想到其他改善强化学习者的方法吗?你能想出更好的方法来解决所提出的井字棋游戏问题吗?
1.6 小结¶
强化学习是一种理解和自动化目标导向学习和决策的计算方法。 它与其他计算方法的区别在于它强调个体通过与环境的直接交互来学习,而不需要示范监督或完整的环境模型。 我们认为,强化学习是第一个认真解决从与环境交互中学习以实现长期目标时出现的计算问题的领域。
强化学习使用马尔可夫决策过程的正式框架来定义学习个体与其环境之间在状态,行为和奖励方面的交互。 该框架旨在表示人工智能问题的基本特征。 这些特征包括因果性,不确定感和不确定性(a sense of uncertainty and nondeterminism),以及明确目标的存在。
价值和价值函数的概念是我们在本书中考虑的大多数强化学习方法的关键。 我们认为价值函数对于在策略空间中高效搜索非常重要。 价值函数的使用将强化学习方法与在整个策略评估指导下直接搜索策略空间的进化方法区分开来。
1.7 强化学习早期历史¶
强化学习的早期历史有两个主线,悠久和丰富,都是在现代强化学习交织之前独立进行的。 一个主线涉及通过试错试验来学习,并且起源于动物学习的心理学。这个主线贯穿了人工智能领域的一些最早的工作,并导致了20世纪80年代早期强化学习的复兴。 第二个主线涉及使用值函数和动态规划的最优控制问题及其解决方案。在大多数情况下,这个主线不涉及学习。 这两个主线大多是独立的,但在某种程度上相互关联,围绕着时序差分方法的第三个不那么明显的线索,例如本章中的井字棋示例中使用的那些。 所有这三个主线在20世纪80年代后期汇集在一起,产生了们在本书中提到的现代强化学习领域。
专注于试错学习的主线是我们最熟悉的,也是我们在这个简短的历史中最可以说的。然而,在此之前,我们将简要讨论最优控制主线。
术语“最优控制”在20世纪50年代后期开始使用,用于描述设计控制器以最小化或最大化动态系统随时间变化的行为的问题。 解决这个问题的方法之一是由理查德·贝尔曼(Richard Bellman)和其他人在20世纪50年代中期 通过扩展19世纪汉密尔顿(Hamilton)和雅可比(Jacobi)理论而发展起来的。 该方法使用动态系统的状态和值函数或“最优返回函数”的概念来定义函数方程,现在通常称为Bellman方程。 通过求解该方程来解决最优控制问题的方法被称为动态规划(Bellman,1957a)。 Bellman(1957b)还引入了称为马尔可夫决策过程(MDPs)的最优控制问题的离散随机版本。 罗纳德霍华德(Ronald Howard,1960)设计了MDP的策略迭代方法。所有这些都是现代强化学习理论和算法的基本要素。
动态规划被广泛认为是解决一般随机最优控制问题的唯一可行方法。它取决于贝尔曼所说的“维度的诅咒”, 意味着它的计算需求随着状态变量的数量呈指数增长,但它仍然比任何其他通用方法更有效,更广泛适用。 动态规划自20世纪50年代后期以来得到了广泛的发展,包括对部分可观察的MDP的扩展(Lovejoy,1991年调查), 许多应用(White,1985,1988,1993),近似方法(由Rust调查,1996)和异步方法(Bertsekas,1982,1983)。 有许多可行的优秀的动态编程现代处理方法 (例如,Bertsekas,2005年,2012年;Puterman,1994; Ross,1983;以及Whittle,1982,1983)。 Bryson(1996)提供了最优控制的权威历史。
最优控制和动态规划之间的联系,以及另一方面的学习,很难被认识到。 我们无法确定这种分离的原因,但其主要原因可能是所涉及的学科与其不同目标之间的分离。 作为一种离线计算,动态规划的普遍观点也可能主要取决于准确的系统模型和Bellman方程的解析解。 此外,最简单的动态规划形式是一种在时间上倒退的计算,使得很难看到它如何参与必须在前进方向上进行的学习过程。 动态规划中的一些最早的工作,例如Bellman和Dreyfus(1959)的工作,现在可能被归类为遵循学习方法。 Witten(1977)的工作(下面讨论)当然有资格作为学习和动态规划思想的组合。 Werbos(1987)明确提出动态规划和学习方法的相互关系,以及动态规划与理解神经和认知机制的相关性。 对于我们来说,动态规划方法与在线学习的完全整合直到1989年Chris Watkins的工作才出现,他们使用MDP形式主义对强化学习的处理已被广泛采用。 从那以后,这些关系得到了许多研究人员的广泛发展,特别是Dimitri Bertsekas和John Tsitsiklis(1996), 他们创造了术语“神经动力学规划”来指代动态规划和人工神经网络的结合。 目前使用的另一个术语是“近似动态规划”。这些不同的方法强调了主题的不同方面,但它们都与强化学习有共同的兴趣来规避动态规划的经典缺点。
从某种意义上说,我们认为所有最优控制工作都应用于强化学习。 我们将强化学习方法定义为解决强化学习问题的任何有效方法,现在很清楚这些问题与最优控制问题密切相关,尤其是随机最优控制问题,例如那些被称为MDP的问题。 因此,我们必须考虑最优控制的解决方法,如动态规划,也是强化学习方法。 因为几乎所有传统方法都需要完全掌握要控制的系统,所以说它们是强化学习的一部分感觉有点不自然。 另一方面,许多动态规划算法是递增的和迭代的。与学习方法一样,他们通过连续的近似逐渐达到正确的答案。 正如我们在本书其余部分所展示的那样,这些相似之处远非肤浅。 完整和不完整知识案例的理论和解决方法是如此密切相关,以至于我们认为必须将它们视为同一主题的一部分。
现在让我们回到导向现代强化学习领域的另一个主要思路,该思路的核心是试错学习的思想。 我们只涉及这里的主要联系点,在第14.3节中更详细地讨论了这个主题。 根据美国心理学家R. S. Woodworth(1938)的说法,试验和错误学习的概念可以追溯到19世纪50年代, 亚历山大·贝恩(Alexander Bain)通过“摸索和实验”讨论学习, 更明确地和英国伦理学家和心理学家Conway Lloyd Morgan的1894年使用该术语来描述他对动物行为的观察进行讨论。 也许第一个简洁地表达试错学习作为学习原则的本质是Edward Thorndike:
在对同一情况作出的若干回应中,那些伴随或密切关注对动物满意的东西,在其他条件相同的情况下,与情况更紧密地联系在一起, 因此,当它再次发生时,它们将更有可能复发; 那些伴随或紧随动物不适的人,在其他条件相同的情况下,会与这种情况的关系减弱, 因此,当它再次出现时,它们不太可能发生。满意度或不适感越大,粘合剂的强化或弱化程度越大。(Thorndike,1911年,第244页)
Thorndike称之为“效果定律(Law of Effect)”,因为它描述了强化事件对选择行为倾向的影响。 Thorndike后来对定律进行了修改,以更好地考虑后续的动物学习数据(例如奖励和惩罚的影响之间的差异), 各种形式的定律在学习理论家中产生了相当大的争议 (例如,见Gallistel,2005;Herrnstein ,1970;Kimble,1961,1967;Mazur,1994)。 尽管如此,效果定律以某种形式被广泛认为是基本原则的基本原则 (例如,Hilgard和Bower,1975;Dennett,1978; Campbell,1960;Cziko,1995)。 它是Clark Hull(1943年,1952年)有影响力的学习理论和B. F. Skinner(1938)的有影响力的实验方法的基础。
在动物学习背景下,“强化”这个术语在Thorndike表达效力定律后得到了很好的应用, 在1927年巴甫洛夫关于条件反射的专着的英文译本中,首先出现在这种背景下(据我们所知)。 巴甫洛夫将强化描述为由于动物接受刺激 - 一种强化剂 - 与另一种刺激或反应有适当的时间关系而加强行为模式。 一些心理学家将强化的观点扩展到包括削弱和加强行为,并扩展强化者的想法,包括可能忽略或终止刺激。 要被认为是增强剂,强化或弱化必须在强化剂被撤回后持续存在;仅仅吸引动物注意力或刺激其行为而不产生持久变化的刺激物不会被视为强化物。
在计算机中实现试错试验的想法似乎是关于人工智能可能性的最早想法。 在1948年的一份报告中,艾伦·图灵(Alan Turing)描述了一种“快乐 - 痛苦系统”的设计,该系统符合效果法则:
当达到未确定动作的配置时,对缺失数据进行随机选择,并暂时在该描述中进行适当的输入并应用。 当疼痛刺激发生时,所有暂定条目都被取消,当快乐刺激发生时,它们都是永久性的。(图灵,1948年)
我们构建了许多巧妙的机电机器以演示试错试验。最早的可能是由托马斯罗斯(Thomas Ross,1933)建造的机器, 它能够通过一个简单的迷宫找到它的路,并记住通过开关设置的路径。 1951年,W. Gray Walter建立了他的“机械乌龟”(Walter,1950)的一个版本,能够进行简单的学习。 1952年,Claude Shannon展示了一只名为Theseus的迷宫老鼠,它使用试错试验通过迷宫找到解决方式, 迷宫本身通过在其地板下的磁铁和继电器记住了成功方向(参见Shannon,1951)。 J. A. Deutsch(1954)描述了一种基于他的行为理论的迷宫解决机器(Deutsch,1953), 它具有与基于模型的强化学习相同的一些性质(第8章)。 在他的博士学位博士论文Marvin Minsky(1954)讨论了强化学习的计算模型,并描述了他的模拟机器的构造, 该模拟机器由他称为SNARC(随机神经 - 模拟增强计算器)的组件组成,其意图类似于大脑中可修改的突触连接(第15章)。 网站 cyberneticzoo.com 包含有关这些和许多其他机电学习机器的大量信息。
建立机电学习机器让位于编程数字计算机以执行各种类型的学习,其中一些学习实现了试错试验。 Farley和Clark(1954)描述了通过试错试验学习的神经网络学习机的数字模拟。 但他们的兴趣很快就从试错学习转向泛化和模式识别,即从强化学习到监督学习(Clark and Farley,1955)。 这开始了对这些类型学习之间关系的混淆模式。许多研究人员似乎相信他们正在研究强化学习,实际他们却在学习监督学习。 例如,Rosenblatt(1962)和Widrow和Hoff(1960)等人工神经网络先驱显然受到强化学习的驱使, 他们使用了奖励和惩罚的语言,但他们研究的系统是适用于模式识别和感知学习(perceptual learning)的监督学习系统。 即便在今天,一些研究人员和教科书也最大限度地减少或模糊了这些学习类型之间的区别, 例如,一些人工神经网络教科书使用术语“试错试验”来描述从训练样本中学习的网络。 这是一个可以理解的混淆,因为这些网络使用错误信息来更新连接权重,但这忽略了试错学习的基本特征, 即在评估反馈的基础上选择行动,而不依赖于知道什么是正确行动。
部分因为这些混淆,对真正的试错学习的研究在20世纪60年代和70年代变得罕见,尽管有明显的例外。 在20世纪60年代,工程文献中首次使用术语“强化”和“强化学习”来描述试错学习的工程用途 (例如,Waltz和Fu,1965; Mendel,1966; Fu,1970;Mendel and McClaren,1970年)。 特别有影响力的是明斯基的论文“迈向人工智能的步骤”(Minsky,1961),该论文讨论了与试错学习相关的几个问题, 包括预测,期望以及他称之为 复杂加强的基本信用分配问题学习系统:你如何在许多可能参与制定它的决策中分配成功的信用? 在某种意义上,我们在本书中讨论的所有方法都是针对解决这个问题的。Minsky的论文今天非常值得一读。
在接下来的几段中,我们将讨论在20世纪60年代和70年代相对忽略对真正的试错学习的计算和理论研究的一些例外和部分例外。
新西兰研究员John Andreae的工作是一个例外,他开发了一种名为STeLLA的系统,该系统通过与环境交互的试错试验来学习。 这个系统包括一个世界的内部模型,后来是一个处理隐藏状态问题的“内部独白”(Andreae,1963,1969a,b)。 Andreae后来的工作(1977)更加强调从老师那里学习,但仍然包括通过试错试验来学习,新一代事件的产生是系统的目标之一。 这项工作的一个特点是“泄漏过程”,在Andreae(1998)中进行了更全面的阐述,实现了类似于我们描述的更新操作的信用分配机制。 不幸的是,他的开创性研究并不为人所熟知,并且对随后的强化学习研究没有太大影响。最近的摘要是可用的(Andreae,2017a,b)。
更有影响力的是Donald Michie的作品。在1961年和1963年,他描述了一个简单的试错学习系统, 用于学习如何玩叫做MENACE(Matchbox Educable Naughts和Crosses Engine)的井字棋(或者naughts和十字架)。 它由每个可能的游戏位置的火柴盒组成,每个火柴盒包含许多彩色珠子,每个可能的移动位置都有不同的颜色。 通过从对应于当前游戏位置的火柴盒中随机抽取珠子,可以确定MENACE的移动。 当游戏结束时,在游戏过程中使用的盒子中添加或删除珠子以奖励或惩罚MENACE的决定。 Michie和Chambers(1968)描述了另一种名为GLEE(游戏学习预测引擎)的强大的井字棋强化学习器和一种名为BOXES的强化学习控制器。 他们将BOXES应用于学习根据仅在杆下落或推车到达轨道末端时发生的故障信号来平衡铰接到可移动推车的杆。 这项任务改编自Widrow和Smith(1964)的早期工作,他使用监督学习方法,假设教师的指导已经能够平衡极点。 Michie和Chambers的杆极平衡版本是在不完全知识条件下强化学习任务的最佳早期例子之一。 它影响了后来的强化学习工作,从我们自己的一些研究开始(Barto,Sutton和Anderson,1983;Sutton,1984)。 Michie一直强调试验和错误以及学习作为人工智能的重要方面的作用(Michie,1974)。
Widrow,Gupta和Maitra(1973)修改了Widrow和Hoff(1960)的最小均方(LMS)算法,以产生一个强化学习规则, 可以从成功和失败信号中学习而不是从训练样例中学习。他们将这种形式称为“选择性自适应适应”, 并将其描述为“与评论家一起学习”,而不是“与老师一起学习”。他们分析了这一规则并展示了它如何学习玩二十一点。 这是Widrow对强化学习的孤立尝试,他对监督学习的贡献更具影响力。 我们对“评论家”一词的使用来源于Widrow,Gupta和Maitra的论文。 Buchanan, Mitchell, Smith, and Johnson(1978)在机器学习的背景下独立使用了术语评论家( 参见Dietterich和Buchanan,1984),但对于他们来说,评论家是一个专家系统,能够做的不仅仅是评估绩效。
学习自动机 的研究对导致现代强化学习研究的试错主线有更直接的影响。 这些是解决非联想性,纯粹选择性学习问题的方法,称为 k型武装强盗,类似于赌博机,或有k杠杆的“单臂强盗”(见第2章)。 学习自动机是简单的低内存机器,用于提高这些问题的奖励概率。 学习自动机起源于20世纪60年代俄罗斯数学家和物理学家M. L. Tsetlin及其同事(于1973年在Tsetlin出版,后期出版)的工作, 并从那时起在工程中得到了广泛的发展(见Narendra和Thathachar,1974,1989)。 这些发展包括随机学习自动机的研究,这是基于奖励信号更新动作概率的方法。 虽然没有在随机学习自动机的传统中发展,但Harth和Tzanakou(1974)的Alopex算法(用于模式提取算法)是一种用于检测行为和强化之间相关性的随机方法, 这些方法影响了我们早期的一些研究(Barto,Sutton和Brouwer,1981)。 早期的心理学研究预示着随机学习自动机,首先是威廉·埃斯特斯(William Estes)(1950)对统计学习理论的研究, 并由其他人进一步发展(例如,Bush和Mosteller,1955;Sternberg,1963)。
经济学研究人员采用了心理学中发展起来的统计学习理论,从而在该领域致力于强化学习。 这项工作始于1973年,将Bush and Mosteller的学习理论应用于一系列经典经济模型(Cross,1973)。 这项研究的一个目标是研究人工个体,其行为更像真实的人,而不是传统的理想经济个体(Arthur,1991)。 这种方法扩展到了博弈论背景下强化学习的研究。 经济学中的强化学习在很大程度上独立于人工智能强化学习的早期工作, 尽管博弈论仍然是这两个领域的一个主题(超出了本书的范围)。 Camerer(2011)讨论了经济学中的强化学习传统, Now ́e,Vrancx和De Hauwere(2012)从我们在本书中介绍的方法的多个体扩展的角度提供了该主题的概述。 在游戏理论的背景下强化是一个非常不同的主题,而不是强化学习在程序中用于玩井字棋,跳棋和其他娱乐游戏。 例如,参见Szita(2012)对强化学习和游戏这一方面的概述。
John Holland(1975)概述了基于选择原则的自适应系统的一般理论。 他的早期工作主要以非关联形式进行试验和错误,如进化方法和k个武装强盗。 1976年,更完全地在1986年,他引入了 分类器系统,这是真正的强化学习系统,包括关联和价值功能。 Holland分类器系统的一个关键组成部分是用于信用分配的“桶 - 旅算法”, 它与我们的井字游戏示例中使用的时序差分算法密切相关,并在第6章中讨论过。 另一个关键组成部分是遗传算法,一种进化方法,其作用是发展有用的表征。 许多研究人员已经广泛开发了分类器系统,以形成强化学习研究的一个主要分支(Urbanowicz和Moore评论,2009), 虽然我们不认为遗传算法本身就是强化学习系统,但它与进化计算的其他方法一样(例如,Fogel,Owens和Walsh,1966,和Koza,1992)受到了更多的关注。
哈利·克洛普夫(Harry Klopf,1972,1975,1982)是负责恢复人工智能中强化学习的试错线索的最负责人。 Klopf认识到,随着学习研究人员几乎专注于监督学习,适应行为的基本方面正在丧失。 根据Klopf的说法,缺少的是行为的享乐方面,从环境中获得某些结果的驱动力,控制环境朝向期望的目的并远离不希望的目的(见第15.9节)。 这是试错学习的基本思想。 Klopf的思想对作者特别有影响,因为我们对它们的评估(Barto和Sutton,1981a)使我们对监督和强化学习之间的区别以及我们最终关注强化学习的理解有所了解。 我们和他的同事完成的大部分早期工作都是为了表明强化学习和监督学习确实是不同的 (Barto,Sutton和Brouwer,1981;Barto和Sutton,1981b;Barto和Anandan,1985)。 其他研究表明,强化学习如何解决人工神经网络学习中的重要问题, 特别是它如何为多层网络提供学习算法(Barto,Anderson和Sutton,1982;Barto和Anderson,1985;Barto,1985,1986;巴托和约旦,1987年;见第15.10节)。
我们现在转向强化学习历史的第三个主线,即关于时序差分学习的历史。 时序差分学习方法的独特之处在于由相同数量的时间连续估计之间的差异驱动 - 例如,在井字棋子示例中获胜的概率。 这个主线比其他两个主线更小,更不明显,但它在该领域发挥了特别重要的作用,部分原因是时序差分方法似乎是强化学习的新特性。
时序差分学习的起源部分在于动物学习心理学,特别是在辅助强化学的概念中。 辅助强化剂是与主要强化物(例如食物或疼痛)配对的刺激物,因此已经具有类似的增强特性。 Minsky(1954)可能是第一个意识到这种心理学原理对人工学习系统很重要的人。 Arthur Samuel(1959)是第一个提出并实施包含时序差分思想的学习方法的人,这是他着名的跳棋游戏计划的一部分(第16.2节)。
Samuel没有提到明斯基的工作或可能与动物学习有关。他的灵感显然来自Claude Shannon(1950)的建议, 即计算机可以编程使用评估功能下棋,并且可以通过在线修改此功能来改进其游戏 (香农的这些观点也有可能影响Bellman,但我们知道没有证据证明这一点)。 Minsky(1961)在他的“步骤”论文中广泛讨论了塞缪尔的作品,暗示了与二级强化理论的联系,包括自然和人工。
正如我们所讨论的那样,在Minsky和Samuel的工作之后的十年中,在试错法学习方面的计算工作很少,显然在时序差分学习上根本没有计算工作。 1972年,Klopf将试错学习与时序差分学习的重要组成部分结合起来 Klopf对可扩展到大型系统学习的原理感兴趣,因此对局部强化的概念很感兴趣,因此整个学习系统的子组件可以相互加强。 他提出了“广义强化”的概念,即每个组成部分(名义上,每个神经元)都以强化术语来看待所有输入:作为奖励的兴奋性输入和作为惩罚的抑制性输入。 这与我们现在所知的时序差分学习并不是同一个想法,回想起它比Samuel的工作更远。 另一方面,Klopf将这一想法与试错学习联系起来,并将其与动物学习心理学的大量经验数据库联系起来。
Sutton(1978a,b,c)进一步发展了Klopf的思想,特别是与动物学习理论的联系,描述了由时间连续预测的变化驱动的学习规则。 他和Barto改进了这些观点,并开发了一种基于时差学习的经典条件心理模型(Sutton和Barto,1981a;Barto和Sutton,1982)。 接下来是基于时序差分学习的几种其他有影响的经典条件心理模型(例如,Klopf,1988;Moore等,1986;Sutton和Barto,1987,1990)。 此时开发的一些神经科学模型在时序差分学习方面得到了很好的解释 (Hawkins和Kandel,1984;Byrne,Gingrich和Baxter,1990; Gelperin,Hopfield和Tank,1985;Tesauro,1986; Friston等,1994), 尽管在大多数情况下没有历史联系。
我们在时序差分学习方面的早期工作受到动物学习理论和Klopf工作的强烈影响。 Minsky的“步骤”论文和Samuel的跳棋运动员的关系后来才得到认可。 然而,到1981年,我们完全了解上面提到的所有先前工作,作为时序差分和试错法主线的一部分。 这时我们开发了一种使用时间差的方法学习与试错学习相结合,被称为 演员 - 评论家架构, 并将这种方法应用于Michie和Chambers的极点平衡问题(Barto,Sutton和Anderson,1983)。 这种方法在Sutton(1984)的博士论文中得到了广泛的研究。论文并扩展到Anderson(1986)博士论文中使用反向传播神经网络。 大约在这个时候,Holland(1986)以他的戽式(bucket-brigade)算法的形式将时序差分思想明确地纳入他的分类器系统。 Sutton(1988)采取了一个关键步骤,将时序差分学习与控制分开,将其作为一般预测方法。 该论文还介绍了TD(\(\lambda\))算法并证明了它的一些收敛性。
当我们在1981年完成关于演员 - 评论家架构的工作时,我们发现了Ian Witten(1977,1976a)的一篇论文, 该论文似乎是时序差分学习规则的最早出版物。 他提出了我们现在称为表格TD(0)的方法,用作解决MDP的自适应控制器的一部分。 这项工作于1974年首次提交期刊出版,并出现在Witten 1976年的博士论文中。 Witten的工作是Andreae早期使用STeLLA和其他试错学习系统进行实验的后代。 因此,Witten的1977年论文涵盖了强化学习研究的主要思路 - 试错法学习和最优控制 - 同时对时序差分学习做出了明显的早期贡献。
1989年,Chris Watkins开发了Q-learning,将时序差分和最优控制线完全结合在一起。 这项工作扩展并整合了强化学习研究的所有三个主线的先前工作。 Paul Werbos(1987)通过争论自1977年以来试错学习和动态规划的融合,为这种整合做出了贡献。 到Watkins的工作时期,强化学习研究已经有了巨大的增长,主要是在人工智能的机器学习子领域, 而且在人工神经网络和人工智能方面也更广泛。1992年,Gerry Tesauro的十五子棋游戏项目TD-Gammon的成功引起了人们对该领域的更多关注。
自本书第一版出版以来,专注于强化学习算法与神经系统强化学习之间的关系的一个神经科学子领域蓬勃发展的。 正如许多研究人员所指出的那样,对此负责的是时间差算法的行为与大脑中多巴胺产生神经元的活动之间的不可思议的相似性 (Friston等,1994;Barto,1995a; Houk,Adams和Barto,1995; Montague,Dayan和Sejnowski,1996;Schultz,Dayan和Montague,1997)。 第15章介绍了强化学习这一激动人心的方面。在最近的强化学习历史中做出的其他重要贡献在这个简短的叙述中无法提及; 我们在其出现的各个章节的最后引用了更多这些内容。
书目备注¶
关于强化学习的其他一般性报道,我们建议读者参考阅读Szepesv ari(2010),Bertsekas和Tsitsiklis(1996), Kaelbling(1993a)以及Sugiyama,Hachiya和Morimura(2013)的书籍。 从控制或操作研究角度出发的书籍包括Si,Barto,Powell和Wunsch(2004),Powell(2011),Lewis和Liu(2012)以及Bertsekas(2012)。 Cao(2009)的综述将强化学习置于其他学习和优化随机动力系统的背景下。 机器学习期刊的三个特刊专注于强化学习:Sutton(1992a),Kaelbling(1996)和Singh(2002)。 Barto(1995b);Kaelbling,Littman和Moore(1996)以及Keerthi和Ravindran(1997)分别提供了有用的调查。 Weiring和van Otterlo(2012)编辑的卷提供了对最近发展的精彩概述。
1.2 本章菲尔早餐的例子灵感来自Agre(1988)。
1.5 第6章介绍了在井字棋示例中使用的时间差分方法。